近日,国际表征学习大会(International Conference on Learning Representations,ICLR)公布了2026年论文录用结果,山东大学-南洋理工大学人工智能国际联合研究院(C-FAIR)有多篇论文被录用。研究成果覆盖多智能体强化学习、因果学习、多模态学习等领域,科研成果如下:
1. GLC
高效和可解释的多智能体通信学习方法。“Learning Efficient and Interpretable Multi-Agent Communication”。论文第一作者为山东大学C-FAIR博士后杜威,通讯作者为崔立真教授。
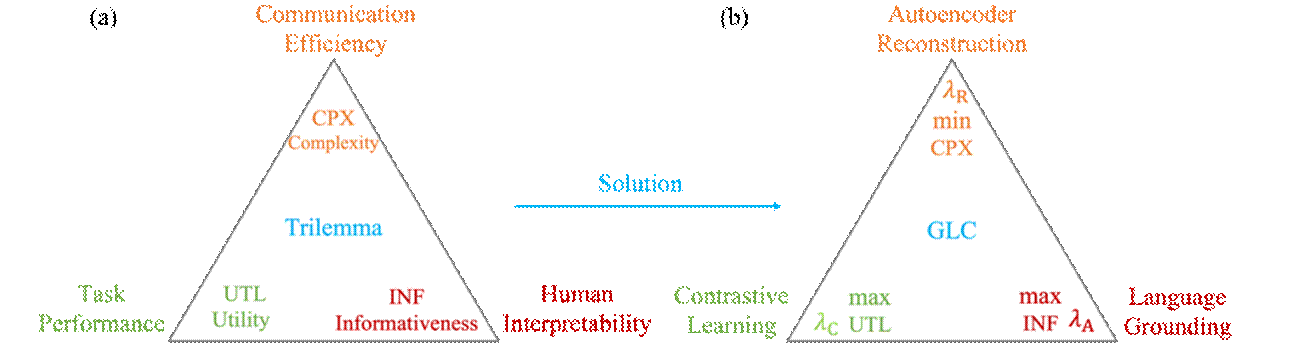
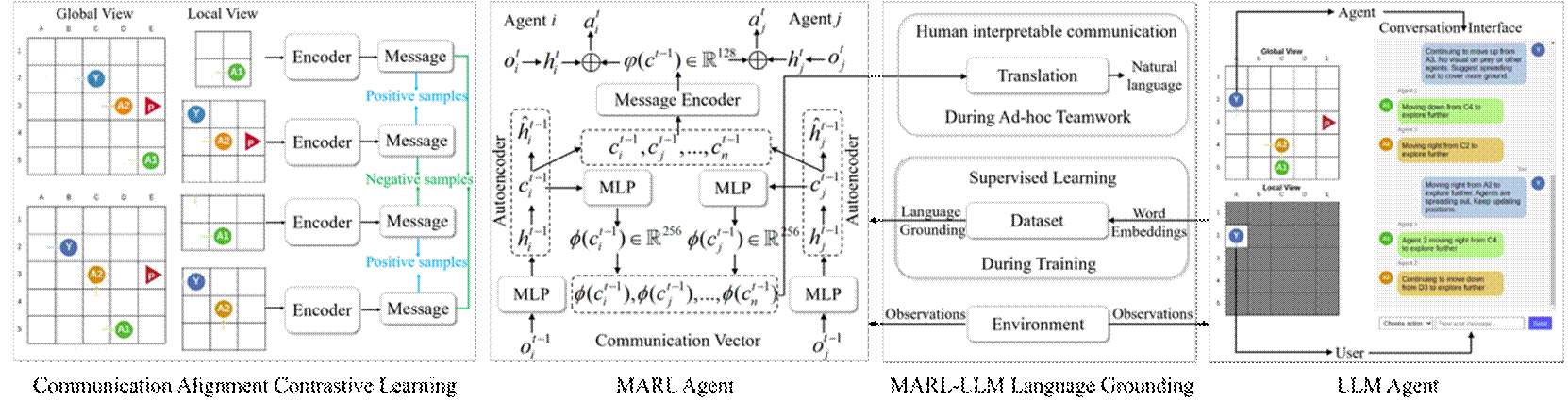
该研究聚焦于多智能体通信学习中存在的任务性能、通信效率与可解释性之间的三难困境,提出一种基于语义接地与对比学习的多智能体通信框架。利用自编码器学习离散化的压缩通信符号,以实现高效的通信传输。通过大语言模型生成的数据,将通信符号与人类可理解的概念在语义层面进行对齐,从而增强系统的可解释性。此外,引入对比学习目标,以促进智能体之间的一致性与相互可理解性,进而保障任务的高性能完成。借助信息瓶颈原则对上述目标进行动态平衡,在复杂多智能体任务中实现了任务性能、通信效率与可解释性的均衡提升。
2. DyCausal
从粗到细的动态因果结构学习。“Coarse-to-Fine Learning of Dynamic Causal Structures”。论文第一作者为山东大学C-FAIR博士研究生杨德智,通讯作者为余国先教授。
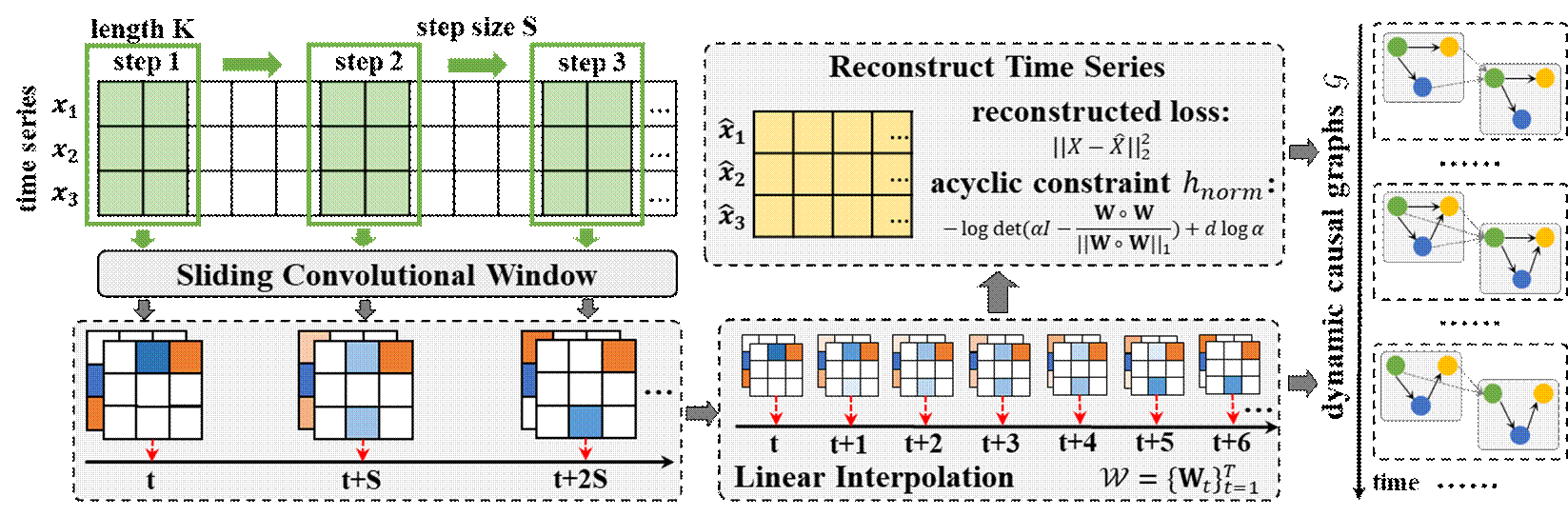
该算法针对现实场景中的复杂因果关系非稳态且难以识别的问题,提出一个完全动态的因果结构学习框架,利用卷积网络来捕捉粗粒度时间窗口内的因果模式,然后在每个时间步应用线性插值来细化因果结构,从而恢复细粒度且随时间变化的因果图。算法还提出一个基于矩阵范数缩放的无环约束,在提高效率的同时有效地约束了不断演变的因果结构中的循环。
3. MASK
面向非配对图文匹配的语义知识对齐框架。“Multimodal Aligned Semantic Knowledge for Unpaired Image-text Matching”。论文第一作者为山东大学C-FAIR博士研究生尹来国,通讯作者为崔立真教授。
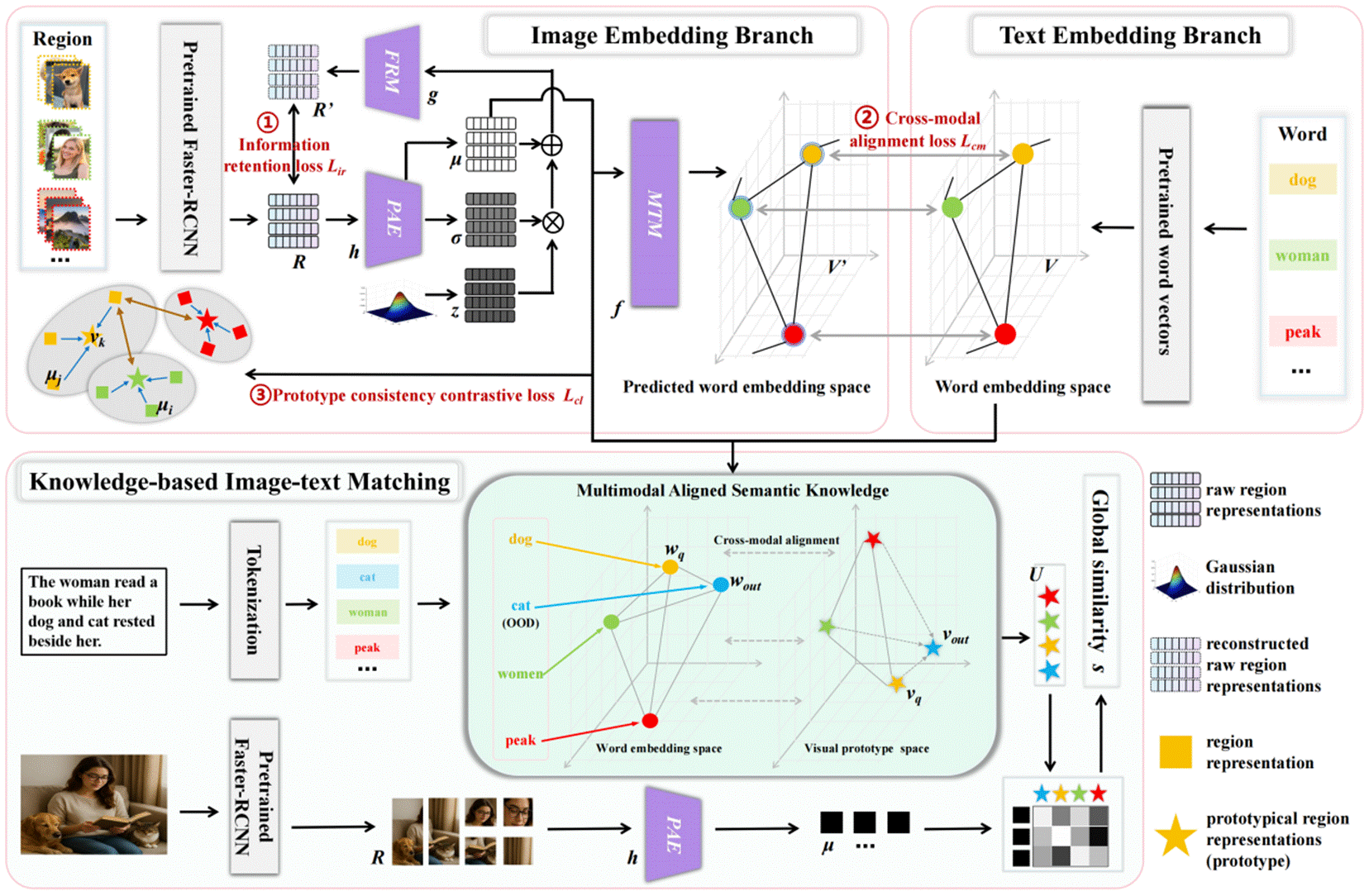
该研究聚焦于非配对图文匹配这一具有重要实际意义但却很少被研究的问题,提出了多模态对齐语义知识框架,利用词嵌入作为桥梁,将词汇与视觉原型关联起来,捕捉词汇之间的语义关系,从而进一步利用 OOD 词汇的信息。此外,原型一致性对比损失的引入有效缓解了非配对匹配中分布差异的影响。
国际学习表征会议(International Conference on Learning Representations,简称ICLR)是由图灵奖得主Yoshua Bengio和Yann LeCun于2013年创立的深度学习领域学术会议,ICLR已发展成为人工智能领域最具影响力的国际学术会议之一,与NeurIPS、ICML并称为机器学习领域三大顶会。ICLR 2026将于2026年4月在巴西里约热内卢举行,ICLR 2026投稿量接近19000篇,接收率创下近年来新低。此次C-FAIR的多项成果入选,彰显了研究院在人工智能前沿领域的科研实力与国际影响力。
