LexPro律智法律大模型由山东大学-南洋理工大学人工智能国际联合研究院(C-FAIR)、软件学院、数据科学研究院依托国家重点研发计划专项课题联合研发,基于海量中文司法语料和有监督司法微调数据训练而成。LexPro的训练语料涵盖故意伤害罪、抢劫罪、合同诈骗罪等20种罪名的各类判决文书,共计百万篇,以及刑法、民法典、宪法及相关司法解释等法律法规。LexPro具备法条检索、法律要素识别、类案推送、案例摘要生成等功能,旨在为检察官等用户提供高精准、全方位的法律咨询与解答服务。
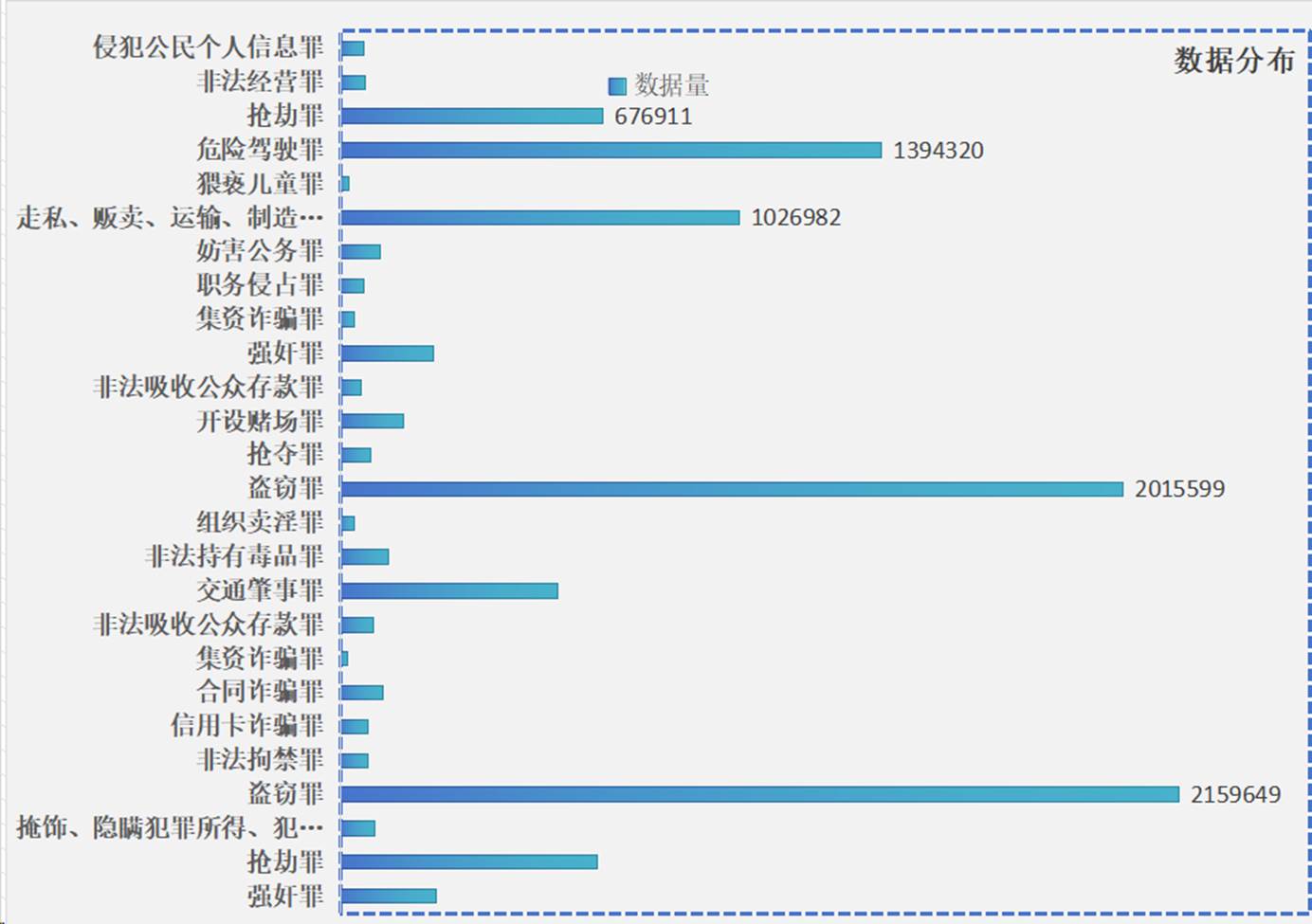
LexPro借助全面的法律专业数据库,通过多维数据体系全面支撑模型能力建设。在数据维度方面:(1)地域覆盖完整,全量收录全国31个省级行政区(不含港澳台)的司法案例资源,形成百万级数据量级;(2)罪名体系完备,重点涵盖故意伤害罪、抢劫罪、诈合同骗罪、盗窃罪等20余个高频刑事案由,并延伸覆盖刑事、行政等全领域纠纷类型;(3)信息颗粒度精细,每份案例均结构化处理为案由要素、判决结果、法条适用等多类属性标签,形成超百万级可解析案件样本。基于海量数据基础,通过多阶段清洗、去重、结构化处理及人机结合标注流程,构建大规模高质量指令微调数据集,使模型不仅具备扎实的法律知识图谱,更能通过监督学习精准掌握法律推理范式。
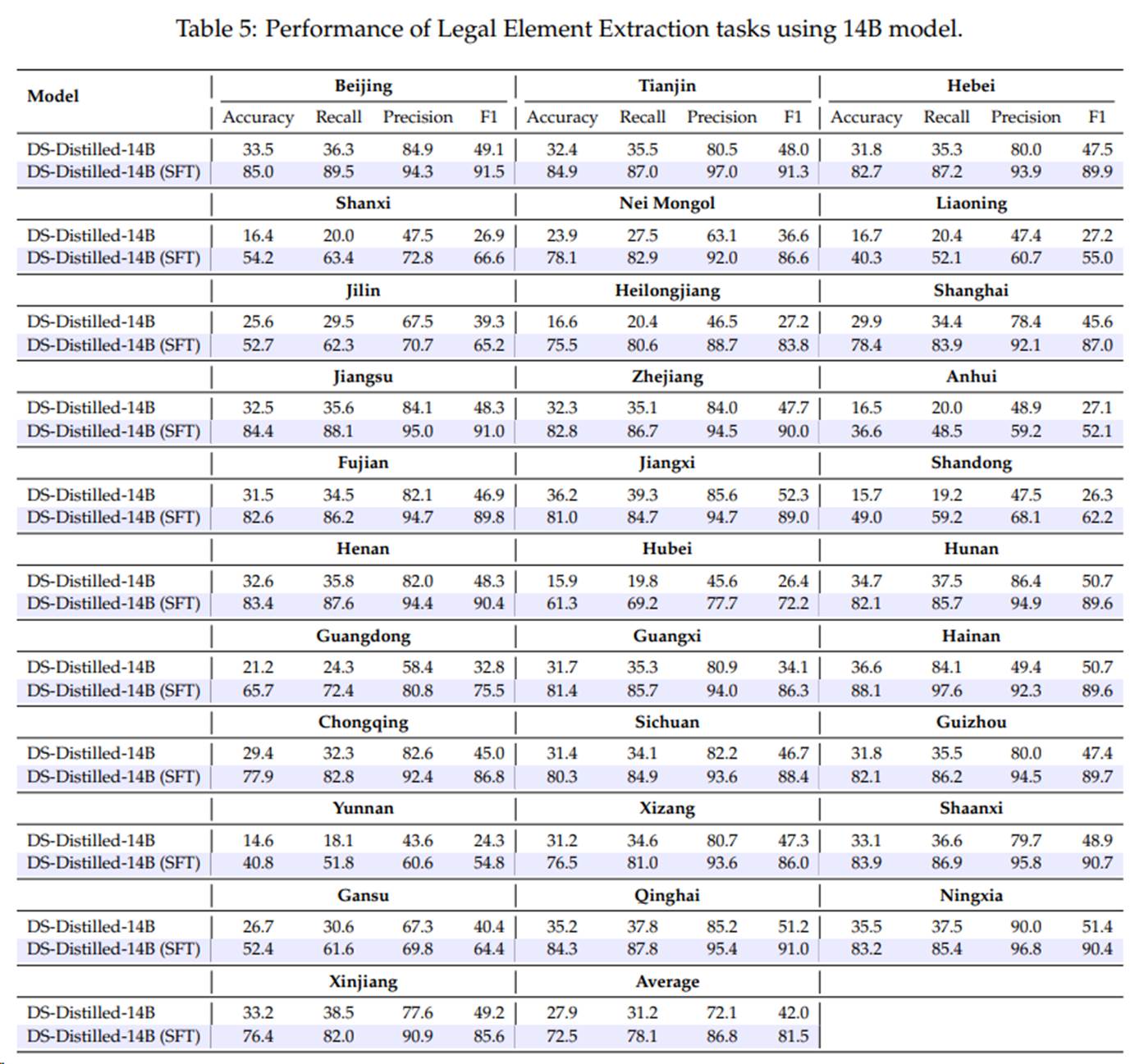
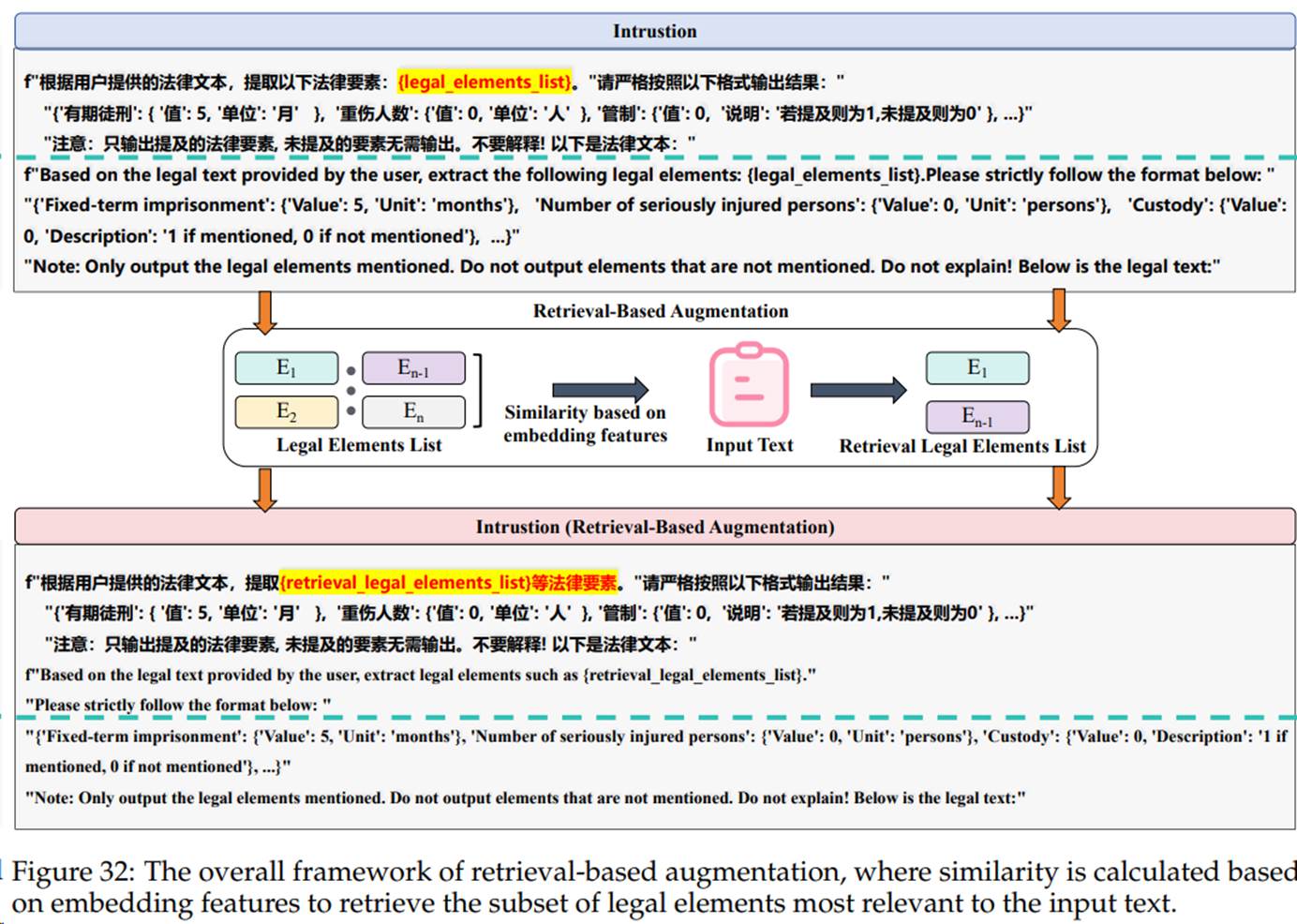
LexPro在大模型训练过程中采用多阶段微调技术,实现法律专业化能力的突破。通过高质量法律指令集的监督微调,构建坚实的法律知识框架。利用大量无标注的裁判文书进行强化学习训练,重点提升法律文本的格式化生成能力和逻辑推理链构建能力,从而显著增强法律文书处理的规范性与一致性。在法律要素识别这一核心任务上,模型创新性地融合了法律条文检索增强机制,在微调阶段动态接入外部知识库,以提升识别准确率。相比基模型,微调后的法律要素识别 F1 指标提升约40%。
LexPro利用国产开源大模型 DeepSeek-R1 的蒸馏模型作为基座,针对高度专业化法律知识进行后训练得到。依托 DeepSeek-R1 强大的思维链能力,该模型具备出色的推理能力,同时计算成本低,适用于高度专业化的检察业务(如法律文书分析、法律要素识别、法条适用推荐等),并可广泛应用于(如检察机关、律所等法律实务场景)。律智-1.0 的研发实现了产、学、研、用一体化发展,推动法律人工智能在实务领域的深入应用。LexPro的详细性能测试报告已发布在Arxiv:https://arxiv.org/abs/2503.06949.
徐庸辉教授团队长期专注于多模态大模型、知识检索增强等前沿技术研究,未来将持续迭代升级律智法律大模型,不断提升其专业性、智能化水平和实际应用能力。相关研究已获得国家重点研发计划、国家自然科学基金项目等资助。
